# Cluster File Organization
### Cluster File Organization
Cluster file organization involves storing two or more related tables or records within the same physical file, known as clusters. The key attributes used to establish relationships between these tables are stored only once, reducing the cost of searching and retrieving records across multiple files.
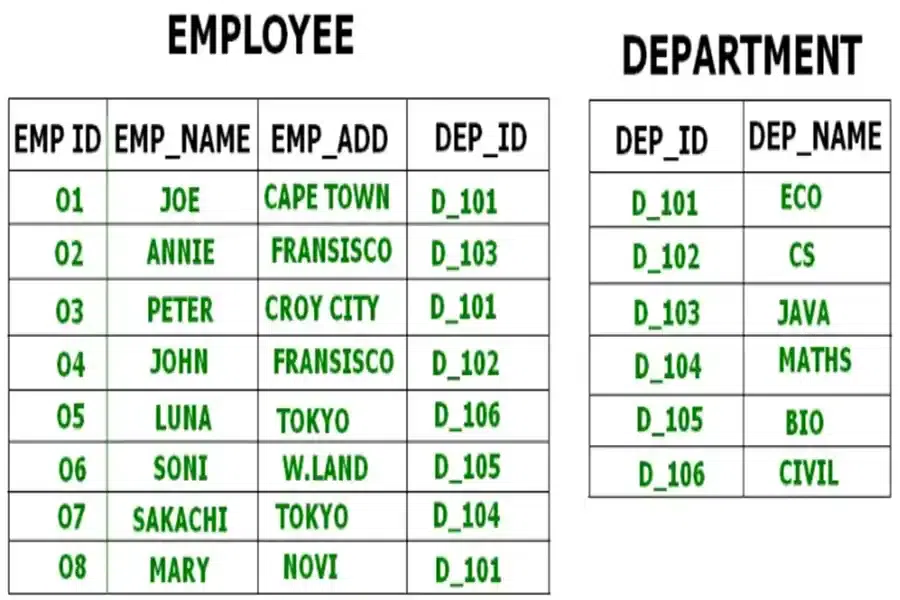
**Example:** Consider two related tables, Employee and Department. These tables can be combined using a join operation and stored in a single cluster file based on a common key, such as Department ID.
 #### Types of Cluster File Organization
There are two primary ways to implement cluster file organization:
1. **Indexed Clusters:** In indexed clustering, records are grouped based on the cluster key (e.g., Department ID in the Employee and Department relationship example). Records with the same cluster key are stored together within the cluster file.
2. **Hash Clusters:** Hash clustering is similar to indexed clustering, but instead of storing records based on the cluster key, a hash function generates a hash key value. Records with the same hash key value are stored together within the hash cluster.
#### Advantages of Cluster File Organization
* **Efficient Join Operations:** Cluster file organization is particularly useful when multiple tables need to be joined using the same join condition. It simplifies and speeds up join operations, as related records are physically stored together.
* **1:m Cardinality:** It performs best when dealing with a one-to-many (1:m) relationship between tables, where one record in the primary table can be associated with multiple records in the related table(s).
#### Disadvantages of Cluster File Organization
* **Performance with Large Databases:** Cluster file organization may exhibit lower performance when dealing with large databases, as managing and maintaining clusters can become complex and resource-intensive.
* **1:1 Cardinality:** In cases where there is a one-to-one (1:1) cardinality between tables, cluster file organization may not provide significant benefits and can be less effective.
Cluster file organization is a valuable tool in database design, especially when optimizing data retrieval for queries that involve multiple related tables. However, it's essential to carefully consider the cardinality of relationships and the size of the database when deciding whether to implement this technique, as it may not always be the best choice for all scenarios.
#### Types of Cluster File Organization
There are two primary ways to implement cluster file organization:
1. **Indexed Clusters:** In indexed clustering, records are grouped based on the cluster key (e.g., Department ID in the Employee and Department relationship example). Records with the same cluster key are stored together within the cluster file.
2. **Hash Clusters:** Hash clustering is similar to indexed clustering, but instead of storing records based on the cluster key, a hash function generates a hash key value. Records with the same hash key value are stored together within the hash cluster.
#### Advantages of Cluster File Organization
* **Efficient Join Operations:** Cluster file organization is particularly useful when multiple tables need to be joined using the same join condition. It simplifies and speeds up join operations, as related records are physically stored together.
* **1:m Cardinality:** It performs best when dealing with a one-to-many (1:m) relationship between tables, where one record in the primary table can be associated with multiple records in the related table(s).
#### Disadvantages of Cluster File Organization
* **Performance with Large Databases:** Cluster file organization may exhibit lower performance when dealing with large databases, as managing and maintaining clusters can become complex and resource-intensive.
* **1:1 Cardinality:** In cases where there is a one-to-one (1:1) cardinality between tables, cluster file organization may not provide significant benefits and can be less effective.
Cluster file organization is a valuable tool in database design, especially when optimizing data retrieval for queries that involve multiple related tables. However, it's essential to carefully consider the cardinality of relationships and the size of the database when deciding whether to implement this technique, as it may not always be the best choice for all scenarios.